Tangoflux AI Text to Audio Generator
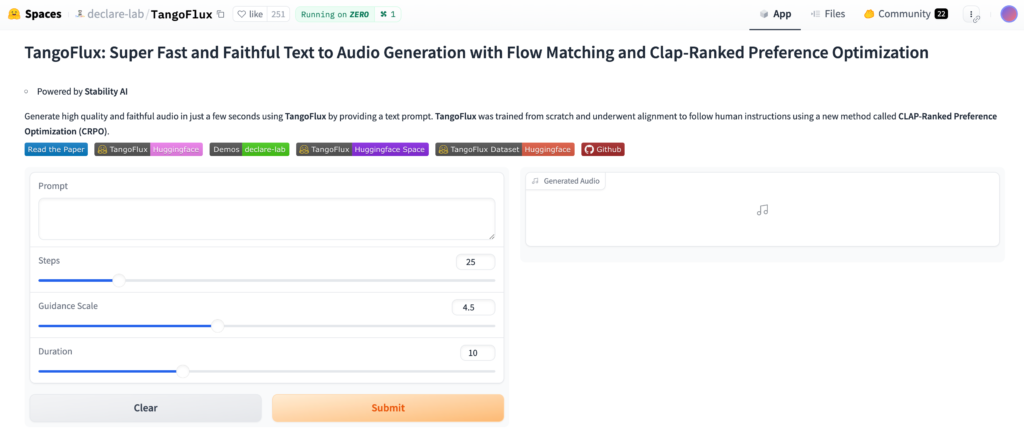
TangoFlux is an open-source text-to-audio model designed to generate realistic and high-quality audio clips from simple text prompts. It can create sounds like music, sound effects, or background audio, with clips lasting up to 30 seconds.
Price: Free
Operating System: Web Application
Application Category: Text to Audio
4
What is Tangoflux AI?
TangoFlux is an open-source text-to-audio model designed to generate realistic and high-quality audio clips from simple text prompts. It can create sounds like music, sound effects, or background audio, with clips lasting up to 30 seconds.
TangoFlux is a versatile tool for content creators, developers, and audio enthusiasts. It supports multiple usage options, including a Hugging Face demo, Google Colab, and local installation, making it accessible for various needs.
Tangoflux Text to Audio Overview
| AI Tool | Tangoflux AI |
| Category | Audio Generator |
| Feature | Text to Audio |
| Accessibility | Online at Hugging Face |
| Functionality | Diffusion model with Unet3D structure |
| Tangoflux Github | Github Repo Link |
Key Features:
- TangoFlux generates high-quality, realistic audio clips from text prompts.
- It supports a wide range of sounds, including music, sound effects, and background audio.
- The model can create audio clips of up to 30 seconds in length.
- It offers fast inference time, enabling quick audio generation compared to other models.
- TangoFlux is open-source, making it freely available for use, modification, and local installation.
- It provides multiple usage options, such as a Hugging Face demo, Google Colab integration, and local setup.
- The model is optimized for efficiency but requires at least 6 GB of RAM for smooth operation.
- TangoFlux has a high CLAP value and a low FD score, ensuring superior audio quality and accuracy.
- It is designed to be user-friendly, with simple text prompts and intuitive interfaces.
- Comprehensive documentation is available on platforms like GitHub and Hugging Face for easy setup and troubleshooting.
-
Realistic Audios
-
Text to Audio Converter
-
Generative Art
-
Free to Use
-
No Watermark
How to Use TangoFlux on Hugging Face?
Using TangoFlux on Hugging Face is simple and straightforward. Here’s a step-by-step guide to help you get started:
Step 1: Visit the Hugging Face Space:
Go to the TangoFlux Hugging Face Space by clicking on this link: https://huggingface.co/spaces/declare-lab/TangoFlux
Step 2: Enter Your Text Prompt:
On the Hugging Face page, you’ll see a text box where you can type your prompt. This prompt should describe the sound you want to generate.
Step 3: Submit the Prompt:
After typing your prompt, click the Submit button. TangoFlux will process your input and generate the corresponding audio clip.
Step 4: Listen to the Generated Audio:
Once the audio is generated, it will play automatically. You can listen to the output and evaluate its quality.
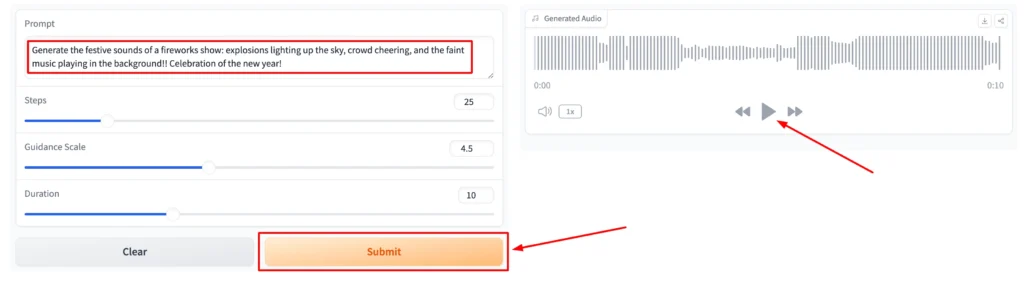
Step 5: Download the Audio (Optional):
If you’re satisfied with the result, you can download the audio clip for use in your projects.
TangoFlux Text to Audio Generator
TangoFlux is an open-source text-to-audio generator that creates realistic and high-quality sound clips from simple text prompts.
TangoFlux Text-to-Audio: How It Works?
TangoFlux is an advanced Text-to-Audio (TTA) generative model designed to create realistic and high-quality audio from text prompts. Here’s a clear, step-by-step explanation of how it works:
Overview of TangoFlux
TangoFlux is a 515-million-parameter model capable of generating up to 30 seconds of 44.1kHz stereo audio in just 3.7 seconds on a single A40 GPU. It addresses a key challenge in TTA models: aligning generated audio with user preferences.
To solve this, TangoFlux introduces CLAP-Ranked Preference Optimization (CRPO), a novel framework that iteratively generates and optimizes preference data to improve alignment.
Step-by-Step Working of TangoFlux
1. Text Input
- Users provide a text prompt describing the desired audio. For example, “A basketball bounces rhythmically on a court, shoes squeak against the floor, and a referee’s whistle cuts through the air.”
2. Audio Generation
- TangoFlux processes the text prompt using its 515M-parameter model.
- It generates up to 30 seconds of 44.1kHz stereo audio in just 3.7 seconds on an A40 GPU.
3. CLAP-Ranked Preference Optimization (CRPO)
- A key innovation in TangoFlux is the CRPO framework, which addresses the challenge of aligning TTA models with user preferences.
- CRPO iteratively generates and optimizes preference data, ensuring the generated audio matches user expectations.
- This framework outperforms existing alternatives in creating high-quality audio preference datasets.
4. Output Delivery
- The generated audio is delivered to the user in high-quality 44.1kHz stereo format.
- Users can listen to, evaluate, and download the audio for their projects.
Salient Features of TangoFlux
- Speed: Generates 30 seconds of 44.1kHz audio in just 3.7 seconds on an A40 GPU.
- Quality: Produces high-fidelity, realistic audio that aligns with user preferences.
- CRPO Framework: Uses CLAP-Ranked Preference Optimization to enhance alignment and audio quality.
- Open-Source: All code and models are open-sourced to support further research in TTA generation.
- State-of-the-Art Performance: Achieves top results in both objective and subjective benchmarks.
TangoFlux Review
TangoFlux Architecture
1. 515M-Parameter Model
- TangoFlux is powered by a 515-million-parameter generative model, which forms the backbone of its text-to-audio capabilities.
- This large-scale model enables the generation of realistic and detailed audio clips.
2. Flow Matching
- TangoFlux utilizes flow matching, a technique that ensures smooth and accurate alignment between text prompts and audio outputs.
- This helps in generating coherent and contextually accurate audio.
3. CLAP-Ranked Preference Optimization (CRPO)
- A key innovation in TangoFlux is the CRPO framework, which addresses the challenge of aligning generated audio with user preferences.
- CRPO iteratively generates and optimizes preference data, ensuring the model produces audio that matches user expectations.
- This framework outperforms traditional methods by creating high-quality audio preference datasets.
4. High-Speed Audio Generation
- TangoFlux is optimized for speed, capable of generating 30 seconds of 44.1kHz stereo audio in just 3.7 seconds on a single A40 GPU.
- This efficiency makes it suitable for real-time applications and large-scale projects.
5. Open-Source Design
- The architecture is fully open-source, allowing researchers and developers to access, modify, and build upon the model.
- This transparency fosters innovation and collaboration in the field of text-to-audio generation.
FAQs:
1. What is TangoFlux?
A: TangoFlux is an open-source Text-to-Audio (TTA) generative model that creates realistic and high-quality audio from text prompts.
2. How does TangoFlux work?
A: TangoFlux uses a 515-million-parameter model to process text prompts and generate audio. It incorporates CLAP-Ranked Preference Optimization (CRPO), a framework that iteratively optimizes preference data to ensure the generated audio aligns with user expectations.
3. What makes TangoFlux unique?
A: TangoFlux stands out for its:
Open-Source: All code and models are publicly available for research and use.
Speed: Generates audio in just 3.7 seconds.
Quality: Produces high-fidelity, 44.1kHz stereo audio.
CRPO Framework: Enhances alignment between text prompts and audio output.
4. What are the system requirements for using TangoFlux?
A: To use TangoFlux locally, you need:
- Python 3.10
- FFmpeg
- Nvidia Graphics Card (e.g., A40 GPU)
- At least 6 GB of RAM
For quick testing, you can use the Hugging Face demo or Google Colab without local installation.
5. Can TangoFlux generate music as well as sound effects?
A: Yes, TangoFlux is versatile and can generate a wide range of audio types, including music, sound effects, and background audio. Simply provide a text prompt describing the desired sound, and TangoFlux will create high-quality audio that matches your description.
Share TangoFlux